OpenSpec 架构
整体架构
可以把它理解成三层:
- 状态层:仓库目录本身就是状态存储
- 计算层:schema + dependency graph + validator
- 交互层:CLI 和 skills,把结构化状态喂给 AI 或人
这套分层很重要,因为它避免了一个常见问题:把“流程”硬编码进 prompt。在 OpenSpec 里,prompt 只是表现层;真正的工作流定义在 schema 中,真正的状态在文件系统里。

核心对象
OpenSpec 其实有4个核心对象:
specs:当前系统行为的 source of truthchanges:待合入的变更包schema:工作流定义,决定有哪些 artifact、它们如何依赖archive:变更完成后的历史沉淀
如果第一次使用,你可能会好奇schema是什么?
在每次变更文件夹中,.openspec.yaml文件中就有 schema字段,默认值为spec-driven。可以在源码中,看到spec-driven定义了产出物(artifacts)的目录、文件名、文件格式、生成Prompt等,以及实施阶段(apply)读取的任务文件和Prompt。
这是OpenSpec预定义的schema,我们也可以自定义schema,对他进行扩展。
工作流
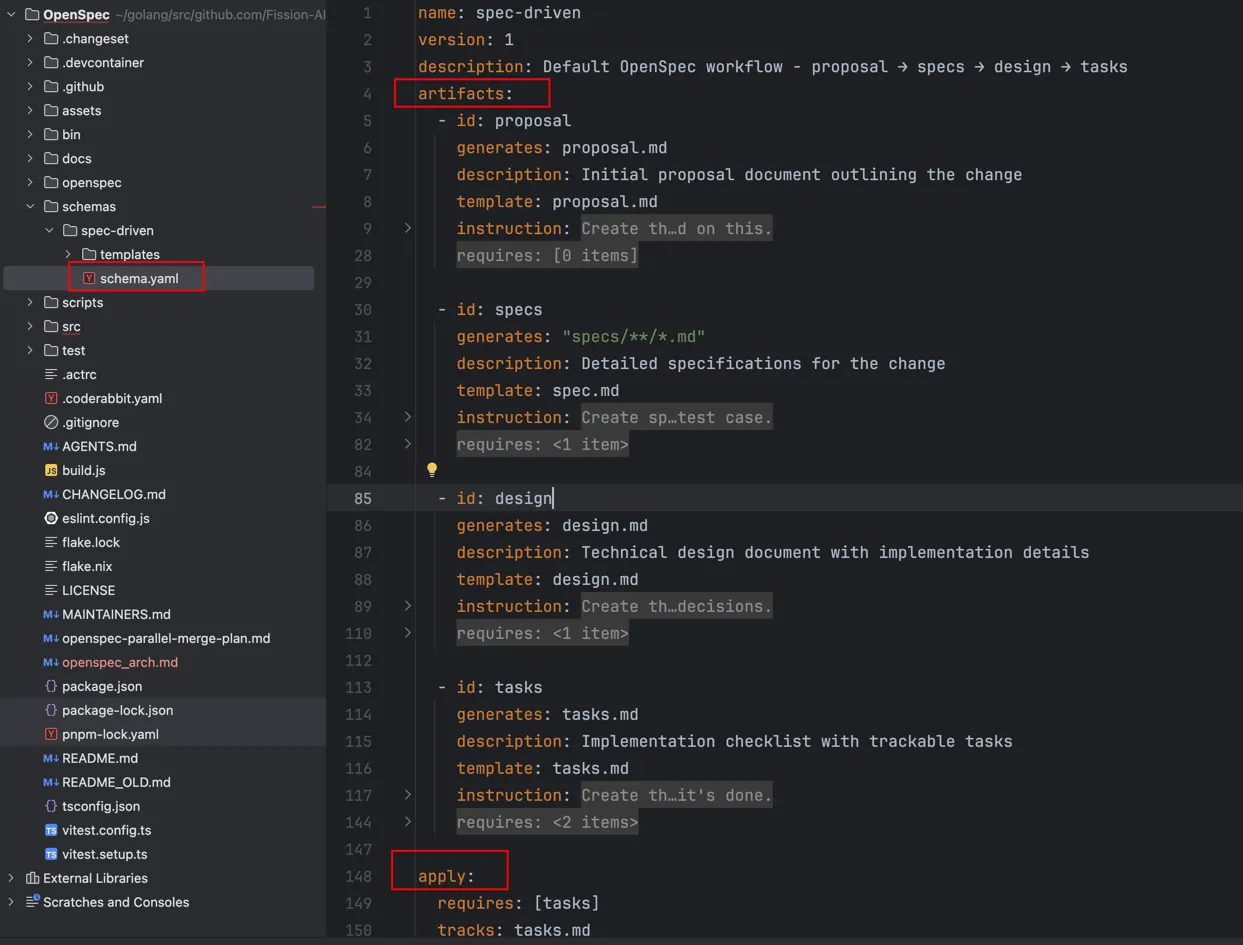
如下是OpenSpec默认的工作流,通过schema定义中的requires字段定义依赖关系。
artifacts:
- id: proposal
generates: proposal.md
requires: []
- id: specs
generates: specs/**/*.md
requires: [proposal]
- id: design
generates: design.md
requires: [proposal]
- id: tasks
generates: tasks.md
requires: [specs, design]
apply:
requires: [tasks]
- 这里的设计哲学:dependency is an enabler, not a gate。
也就是说,依赖表示“现在什么是可做的”,而不是“你必须严格按唯一顺序前进”。这和很多传统 spec 流程差异很大:后者把流程建模成 phase,前者把流程建模成 action + dependency。
这是一个非常适合 AI 协作的建模方式,因为真实开发本来就不是线性的。你今天写完 design,明天发现 assumptions 错了,回头改 spec,这很正常。OpenSpec 没有试图消灭这种回流,而是承认它。
- 扩展性好。可以很方便的扩展自定义的artifacts
比如,希望添加“test_case”编写环境,只需要按照已有artifacts格式,定义清楚“requires”、“instruction”等信息即可
状态机:blocked / ready / done
以默认schemaspec-driven为例,执行 opsx:propose命令后,artifacts依赖关系如下图:
那他们是是怎么驱动的呢? OpenSpec 的状态模型定义了 3 个主状态:
一句话,status 决定该不该做。 也就是,specs和design 状态都为done,那么“tasks”才可以执行。从而实现了“状态驱动”。 这里有一个很值得注意的设计选择:OpenSpec 的状态不是“保存在某处”,而是“计算出来的”。这意味着不需要额外的状态存储
这种推导模式,适合轻量状态,也不用考虑状态一致性问题。不太适合复杂的过程型状态,比如,审批流。
动态指令(Prompt)生成:CLI 不是“命令行外壳”,而是 AI 的结构化上下文提供者
在很多工具里,AI 拿到的是一段固定 prompt;但 OpenSpec 的 openspec instructions 做了更有意思的一层:定义标准结构体ArtifactInstructions,根据当前 change 的实时状态,生成一个包含依赖、模板、规则、输出位置的结构化指令包,然后以 JSON 输出给 AI。
如下为源码中Artifact Instructions定义。源码路径:src/core/artifact-graph/instruction-loader.ts
/**
* Enriched instructions for creating an artifact.
*/
export interface ArtifactInstructions {
/** Change name */
changeName: string;
/** Artifact ID */
artifactId: string;
/** Schema name */
schemaName: string;
/** Full path to change directory */
changeDir: string;
/** Output path pattern (e.g., "proposal.md") */
outputPath: string;
/** Artifact description */
description: string;
/** Guidance on how to create this artifact (from schema instruction field) */
instruction: string | undefined;
/** Project context from config (constraints/background for AI, not to be included in output) */
context: string | undefined;
/** Artifact-specific rules from config (constraints for AI, not to be included in output) */
rules: string[] | undefined;
/** Template content (structure to follow - this IS the output format) */
template: string;
/** Dependencies with completion status and paths */
dependencies: DependencyInfo[];
/** Artifacts that become available after completing this one */
unlocks: string[];
}
定义了几类信息:
- 当前 artifact 是什么
- 输出文件应该写到哪里
- 依赖 artifact 是否已完成
- 需要先读哪些文件
- 当前 schema 下的模板内容
- 项目级
context和 artifact 级rules - 完成该 artifact 后会解锁哪些下游 artifact
换句话说,OpenSpec 的 CLI 在做的不是“执行命令”,而是在做workflow context serving。
这很重要,因为 AI 最怕两件事:
- 看不到当前状态
- 看不到当前动作的边界
而 status + instructions 组合,本质上就是把这两个问题结构化了。
项目特有约束:context 和 rule
context:项目级、全局共享的背景信息,会注入到所有 artifact 的 instructions。适合放所有 artifact 都需要知道的项目事实和长期约束。 当前context限制:
- 只支持字符串
- 支持多行
- 支持特殊字符
- 最大 50KB
- 太大会被忽略并报警告
rules:artifact 级、按类型区分的附加规则,只会注入到匹配的 artifact,比如只对 design 或 tasks 生效。
context 和 rules 该怎么分工?一个简单判断方法: 放进 context 的内容 满足下面任一条件,就更适合放 context:
- 所有 artifact 都应该知道
- 是稳定的项目事实
- 是跨阶段都适用的团队约束
- 更像“项目背景”而不是“这份文档怎么写” 典型内容:
- 技术栈
- 目录结构
- 架构风格
- 测试/可观测性/安全基线
- 术语和业务边界
- 团队通用编码规范
放进 rules 的内容 满足下面任一条件,就更适合放 rules:
- 只针对某一类 artifact
- 是输出格式或内容检查点
- 是“proposal 应该写什么 / design 必须说明什么 / tasks 如何拆” 典型内容:
- proposal 必须写回滚影响
- specs 必须用 SHALL/MUST
- design 必须解释边界与迁移
- tasks 必须拆到可执行、可验证
OpenSpec是workflow
以 “opsx:propose” 为例。/opsx:propose 负责“编排流程”,依次执行下面的命令:
openspec new change "<name>",创建新的 changeopenspec status --change "<name>" --json,计算“下一个生成的 artifact 是谁”?openspec instructions <artifact-id> --change "<name>" --json,生成 artifact instructions
“opsx:propose” 依次生成4个artifact:proposal、specs、design、tasks
二、给我们的启示
2.1 把状态外化到仓库,而不是埋在会话里
这是 OpenSpec 最强的一点。
| 设计 | 解决了什么 | 启示 |
|---|---|---|
| 文件系统承载状态 | 状态可见、可复算、可进入 Git 历史 | 对 AI 工作流来说,外显状态比“更聪明的 prompt”更重要 |
| specs / changes 分离 | 当前事实与待变更解耦,支持并行变更 | 不要让“讨论中的方案”直接污染 source of truth |
| schema 驱动 artifact graph | 工作流可定制,不必改代码 | 把流程定义数据化,比把流程写死在代码里更能长期演进 |
| delta spec 合并 | 对 brownfield 修改极友好 | 在存量系统里,差量建模通常比全量建模更实用 |
| CLI 生成结构化 instructions | 给 AI 明确边界和上下文 | AI 工具真正需要的不是更多 prompt,而是更好的上下文接口 |
2.2 “state-first”,而不是“spec-first”
很多人会把 OpenSpec 看成 spec-first 工具,但我觉得更准确的说法是:它是一个 state-first 的 AI 协作框架。
原因很简单:
- spec 只是 artifact 之一 ,design、tasks、proposal 也都是 artifact
- 真正驱动流程的不是文档内容本身,而是artifact 之间的依赖关系和当前完成态
这带来一个很实用的启示:
对 AI 协作流程来说,最值钱的不是“把文档写标准”,而是“把下一步动作计算出来”。
一旦系统能稳定回答下面两个问题,协作效率就会明显上升:
- 我现在处于什么状态?
- 我下一步最合理的动作是什么?
OpenSpec 的 status / instructions / apply,本质上都在回答这两个问题。
2.3 “迭代”开发,而不是“线性”开发
传统流程工具喜欢 phase gate,因为它好管理;但实际开发中,需求和理解总是在变化,可能需要不断修改设计和实现。
OpenSpec OPSX Workflow :
- 不强调 phase 强调 action
- 允许在实现过程中回头改 design / spec / tasks

例子:需要修改design,并级联更新spec和task,修改对应实现
“由于性能问题,请把我们的分页方案从‘偏移量分页’改为‘游标分页’。请执行以下步骤:1. 更新 design.md; 2. 基于新的设计,同步修改 specs 下的测试用例; 3. 更新 tasks.md,把旧的 API 修改任务替换为新的游标分页任务。”
这是一个非常成熟的 trade-off:
- 优点:贴近真实开发,尤其适合 agent + 人类的往返协作
- 缺点:治理更弱,流程纪律更多依赖团队共识,而不是系统强制
这也给团队设计流程一个提醒:
越贴近真实认知过程的流程,往往越不“整齐”;但它通常更高效。
2.4 它把“可扩展性”放在核心层,而不是集成层
系统设计中,像六边形架构、洋葱模型、DDD等,都是将“可扩展性”放在非核心层,通过“Interface”隔离。 OpenSpec 更深一层,它把扩展性放在:
- 模板可扩展
- 工作流依赖可扩展
- artifact 类型可扩展
- 项目规则可扩展
这比“再适配一个新的外部依赖”有含金量得多。 因为真正昂贵的从来不是接一个新入口,而是让系统核心抽象在新场景下仍成立。
三、目前的不足
OpenSpec 的设计方向是对的,但如果站在更严格的工程视角看,它现在也有一些很明显的边界。
3.1 done 的定义过于乐观
当前完成态基本由“产出文件是否存在”决定。
这很优雅,但也很脆弱。因为下面这些情况都会被误判为完成:
- 文件只是模板骨架,还没填实质内容
- spec 已经改了,但 tasks 没刷新
- design 存在,但已经和 proposal 脱节
- 生成了
tasks.md,但里面没有有效任务
也就是说,OpenSpec 目前更像在追踪artifact existence,而不是 artifact validity / freshness。
如果继续演进,我认为最值得补的是一个“脏态”体系,例如:
done:存在且通过基础校验stale:上游依赖变化后需要重审invalid:结构存在但不满足 schema / validator
没有这层能力,状态驱动会很容易滑向“文件驱动”。
实际使用中,你也会发先,如果发现代码实现不符合预期,你修改了spec,缺少一种机制同步到task。如果直接改task,task又不能反向更新spec
3.2 依赖图解决了顺序问题,但还没解决“同步失效”问题
当前图模型非常适合表达“谁先于谁”,但不太能表达“谁因为谁变化而失效”。
例如:
- proposal scope 变了,spec 是否应该自动标记为 stale?
- spec requirement 改了,tasks 是否需要重新生成?
- design 改了,apply 阶段是否应该阻塞直到任务同步?
这类问题本质上不是 DAG 的可达性问题,而是变更传播和一致性问题。
OpenSpec 现在已经有“dependency as enabler”,下一步更难、也更关键的是“dependency as invalidation source”。
3.3 Delta merge 以 requirement 标题为锚点,足够实用,但不够强壮
OpenSpec 在 archive 时按 requirement block 合并,这是个很好的方向;但它目前主要依赖 requirement header 做匹配。
这会带来几个天然风险:
- requirement 标题改写后,merge 容易脆弱
- 大规模编辑时,rename / modify 冲突规则会变复杂
- 多个变更同时改同一 requirement,冲突解析成本会上升
从工程角度看,这其实意味着它还缺少一个更稳定的逻辑主键,例如 requirement ID。
也就是说,现在的实现更像:
- 面向人类可读性优化
- 还没有完全走到面向机器稳定性优化
这是合理的早期 trade-off,但如果要支撑更大规模协作,这一步迟早要补。
3.4 文件系统状态机很轻,但并发与事务语义较弱
文件系统做状态后端的优点很多,但它的短板也很明确:
- 缺少强事务边界
- 多人并行编辑时,冲突靠 Git,而不是工作流层解决
- 很难表达更复杂的审核流、审批流、租约流
- archive / apply 虽然已经尽量先验证后写入,但仍是多文件操作
所以我会把 OpenSpec 看成一个单仓库、轻协调、Git 友好的工作流系统,而不是一个严肃的流程编排平台。
这不是批评,而是边界判断。
3.5 当前验证更偏“结构正确”,还不够“语义闭环”
OpenSpec 已经有 validator,也有 verify/apply 这类动作,但从整体上看,它现在更擅长检查:
- 结构是否符合模板
- delta 是否合法
- spec 是否能被归档合并
但它还没有真正闭环到:
- requirement 是否被代码覆盖
- tasks 是否与实现一致
- 变更是否满足可测试性与可验证性
- spec / code / test 三者之间是否能建立稳定 traceability
而这恰恰是下一阶段最值得做的地方。
如果未来能把 requirement、实现、测试、归档历史串成一条可追踪链路,OpenSpec 的价值会从“AI 协作工具”进一步提升成“变更控制基础设施”。
结语
我对 OpenSpec 的整体评价依然很高,它抓住了一个非常正确的方向:
把 AI 协作从“依赖上下文记忆”推进到“依赖可计算状态”。
在我看来,OpenSpec 最有价值的三个架构点是:
- 把工作流定义从代码里抽成 schema
- 把协作状态外化到仓库结构里
- 把 brownfield 变更建模成 delta,而不是全量重写