通过 SDD + OpenSpec,我们在一个真实的存量项目中,用 AI 生成了 9600+ 行可编译、可测试的代码,手动修改不到 50 行。本文记录了完整的实践过程、评测结果和踩坑经验。
什么是SDD
从 Vibe Coding 说起
2024年底,Andrej Karpathy 提出了一个概念——Vibe Coding(氛围编程):
“你完全沉浸在’氛围’中,拥抱指数级增长,忘记代码的存在。就是跟AI对话、让它干活、看看结果、反复迭代。”
在2025年,我也在多种场景下使用 Vibe Coding,但实际企业项目更注重确定性、规范性、可维护性,小范围的 Vibe Coding 确实有效——比如:明确函数定义后补充实现、编写单测等。但一旦把范围扩展到复杂需求、项目重构时,就失效了。也尝试过编写面向场景的 Agent,但结果还是差强人意。
反复碰壁后,我总结出 Vibe Coding 在企业项目中失败的三个根本原因:
- 上下文丢失(Lost in the Middle):复杂任务需要多轮对话,但随着对话轮次增加,AI 开始”遗忘”前面的约定——前后矛盾、反复纠正,效率急剧下降。
- 领域知识缺失:复杂项目往往有复杂的业务背景、技术约定和关联知识(如内部框架的使用规范、团队的分层架构约定等),纯对话的方式很难将这些隐性知识完整地传递给 AI。
- 缺乏结构化约束:AI 每次生成的代码风格、架构决策不一致。简单功能还好,复杂逻辑频繁出错,调 Bug 的时间甚至超过手写。项目规模越大,”改一处坏十处”的问题越严重。
归结为一句话:Vibe Coding 给了 AI 自由度,却没给它约束。
SDD的定义与核心思想
Spec-Driven Development(SDD) 是2025年兴起的一种通过结构化规范文档驱动AI生成代码的开发范式。
核心理念:
人定义 "What"(做什么)和 "Constraints"(约束条件)
AI负责 "How"(怎么实现)
如果做一个类比:
| 范式 | 类比 | 特点 |
|---|---|---|
| Vibe Coding | 跟AI口头聊需求 | 自由但不可控 |
| SDD | 给AI一份详细的设计说明书 | 有约束但可控 |
SDD之于AI编程,类似于TDD之于传统开发——都是通过”先定义预期”来约束”实现过程”。
SDD 中的 “S” 怎么理解
对照熟悉的TDD、BDD,SDD 的 S(Spec) 本质上是一份给 AI 的完整工作说明书,它比 TDD 的测试用例更宽(不仅定义验证标准,还定义架构约束、技术选型、编码规范),比 BDD 的 Feature 文件更深(不仅描述业务行为,还包含实现层面的技术约束)。
三者是传承演进关系,而非互相替代:
- TDD 说的是”代码该怎么跑”(面向机器验证)
- BDD 说的是”功能该怎么表现”(面向人机共识)
- SDD 说的是”AI 该怎么干活”(面向 AI 约束)
💡 SDD 可以利用 TDD、BDD 进一步明确需求,消除歧义和不确定性。实际上,OpenSpec 的 spec.md 中 Requirement + Scenario 的写法,正是 BDD 的影子。
什么场景适合引入 SDD
SDD 不是银弹,它有明确的适用范围(详见文末”能力边界”章节)。简单判断:
- ✅ 值得用:需求可以被结构化描述、项目有明确架构规范、团队多人协作
- ❌ 不必用:探索性原型、一次性脚本、小范围 hotfix
- 📌 核心判断标准:如果你能写清楚”做什么”和”约束是什么”,SDD 就能帮你;如果需求本身都说不清,先理清需求再说
SDD 带来的核心价值
从本质上看,SDD 属于 Context Engineering(上下文工程) 的范畴。如果说 Prompt Engineering 关注的是”怎么问 AI 一个好问题”,那么 Context Engineering 关注的是”怎么给 AI 构建一个好的工作环境”。SDD 正是通过结构化的 Spec 提供丰富、准确、持久的上下文,使 AI 在更受控的条件下工作。
| Vibe Coding 痛点 | SDD 的解法 | 延伸价值 |
|---|---|---|
| 上下文丢失 | Spec 文件持久化上下文,不依赖对话记忆 | 可追溯性:需求 → 规范 → 代码,每一步有据可查 |
| 领域知识缺失 | config.yaml + specs/ 注入领域知识 | 团队协作:Spec 成为团队共识的载体 |
| 缺乏结构化约束 | Spec 定义明确的输出边界 | 可控性 + 可复现性:相同 Spec 产出一致质量的代码 |
选型 / 业界有哪些解决方案
目前业界和司内有不少SDD实践,主要有三个 SDD 方案值得关注:OpenSpec、Spec-Kit 和 Kiro。
方案一览
| 维度 | OpenSpec | Spec-Kit | Kiro |
|---|---|---|---|
| 作者 | Fission AI(社区) | GitHub(官方) | AWS(官方) |
| 形态 | CLI 工具 + AI 斜杠命令 | CLI 工具 + AI 斜杠命令 | 独立 IDE + CLI |
| 运行时 | Node.js ≥ 20.19 | Python 3.11+ / uv | 独立应用(VS Code 兼容) |
| 设计哲学 | 事务性 Delta(只记变更差异) | 宪法治理(constitution.md 约束全局) | 集成式 Spec(Prompt → Spec → 代码一站式) |
| 工作流 | 3 步循环:Proposal → Apply → Archive | 6 阶段流水线:Init → Constitution → Spec → Plan → Tasks → Implement | 线性流:需求描述 → 结构化 Spec → 架构设计 → 任务拆解 → Agent 实现 |
| 规范格式 | 自定义 Markdown(Requirement + Scenario) | 每阶段独立文档 | EARS 表示法(Event-Action-Response-State) |
| Agent 支持 | 12+ 原生斜杠命令(Claude Code、Cursor 等) | 25+(几乎所有主流 Agent) | 仅限 Kiro 内置 Agent |
| 扩展生态 | 精简,无扩展体系 | 丰富,40+ 社区扩展 | 内置 Agent Hooks + MCP 集成 |
| Token 效率 | ⭐⭐⭐ 高(Delta 传输) | ⭐ 低(全量规范) | ⭐⭐ 中(IDE 自行管理上下文) |
| 上手成本 | ⭐ 低 | ⭐⭐ 中等 | ⭐ 低(IDE 自带引导) |
| 锁定风险 | 低(标准 Markdown 文件) | 低(标准文件 + Python 工具) | 高(绑定 Kiro IDE) |
适用场景与局限性
| 方案 | 最佳场景 | 局限性 |
|---|---|---|
| OpenSpec | 🟢 存量项目持续迭代(Brownfield);希望在现有 IDE/Agent 中使用 SDD | 社区较小,治理能力弱,需团队自律维护 Spec |
| Spec-Kit | 🟢 新项目从零构建(Greenfield);大团队需要强治理和流程规范 | 流程较重,简单需求也要走完整流水线;Python 依赖 |
| Kiro | 🟢 个人/小团队全新项目;希望开箱即用的一站式体验 | 绑定 Kiro IDE,无法在 Cursor/VS Code/Claude Code 中使用;Spec 变更分散在多个文件夹,不如 OpenSpec 按 Feature 聚合 |
我们的选择
本文选择 OpenSpec 作为重点介绍对象,原因:
- 我们的场景以存量项目迭代为主,OpenSpec 的 Delta 模型更契合
- 不绑定特定 IDE,可与 Claude Code、codebuddy 等自由组合
- Token 效率高,在大型项目中优势明显
💡 三者并非对立关系。理论上可以用 Spec-Kit 做项目初始化建立治理规范,后续用 OpenSpec 做持续迭代。
OpenSpec 深度解析
架构
OpenSpec 采用双目录模型,核心思想是将"正式规范"与"变更提案"显式分离:
openspec/
├── specs/ # 📚 正式规范(Source of Truth)
│ └── [domain]/
│ └── spec.md # 某领域的完整规范
├── changes/ # 📝 变更提案(进行中的修改)
│ └── [feature-name]/
│ ├── proposal.md # 变更提案:做什么、为什么
│ ├── tasks.md # 实现任务列表
│ ├── design.md # (可选)设计文档
│ └── specs/
│ └── [domain]/spec.md # Delta:只包含本次变更的差异
├── archive/ # 📦 已完成的变更归档
└── config.yaml # 🤖 项目上下文信息,会主动注入到每个 OpenSpec 规划请求中
关键设计:
Delta而非全量:
changes/中的 spec 文件只包含ADDED、MODIFIED、REMOVED的部分,而非完整规范的副本。这大幅减少了token消耗。按 Feature 组织变更:每个feature一个文件夹,包含完整的提案-任务-差异链路,便于追溯。
使用流程
OpenSpec 最新的工作流引擎叫 OPSX,它与传统瀑布式流程有本质区别:
| 传统瀑布流 | OPSX | |
|---|---|---|
| 推进方式 | 阶段锁定,必须按顺序完成 | “Actions, not phases”,满足前置条件即可执行任意动作 |
| 迭代成本 | 回到上一阶段代价高 | 随时修改proposal,更新specs,自然迭代 |
| 产物粒度 | 所有文档一次性生成 | 可逐个生成spec(原子化),也可批量生成 |
核心命令
日常使用只需 3 个命令:
| 命令 | 作用 | 说明 |
|---|---|---|
/opsx:propose | 提案 | 创建变更 + 规划产物(proposal、tasks、spec delta) |
/opsx:apply | 实施 | 按 tasks 执行实现,逐个标记完成 |
/opsx:archive | 归档 | 将 delta 合并到正式 specs,标记变更完成 |
想更细粒度控制?
/opsx:explore仔细思考,明确需求;/opsx:continue(逐个产物推进)和/opsx:ff(一键快进全部规划产物)灵活切换。
“快进”与”原子化”的平衡
这是 OPSX 最实用的设计——根据你对需求的信心程度选择推进速度:
- 信心高、scope 清晰 →
/opsx:ff一键快进,批量生成所有规划产物,最大化效率 - 需要逐步验证 →
/opsx:continue一次生成一个产物,审查通过后再推进下一个 - 需求还在摸索 →
/opsx:explore先自由探索,想清楚了再进入结构化流程
实际工作中,三种模式经常交替使用:先 explore 理清思路,propose 后 ff 快速生成规划,apply 阶段发现问题则回头修改 spec 重新 apply——不是线性流水线,而是有状态感知的灵活迭代。
实际使用
⚠️ 以下案例为实际项目中的使用体验,包含真实的需求、生成结果和评测。
需求1:推荐分发服务升级(分发字段管理部分)
需求实现
需求描述: 推荐分发服务,需要将分发的字段管理起来,记录每个订阅方使用了哪些字段。“分发字段管理”功能,涉及13个接口,5张数据表。
Spec文件编写:
如下初始的propose:
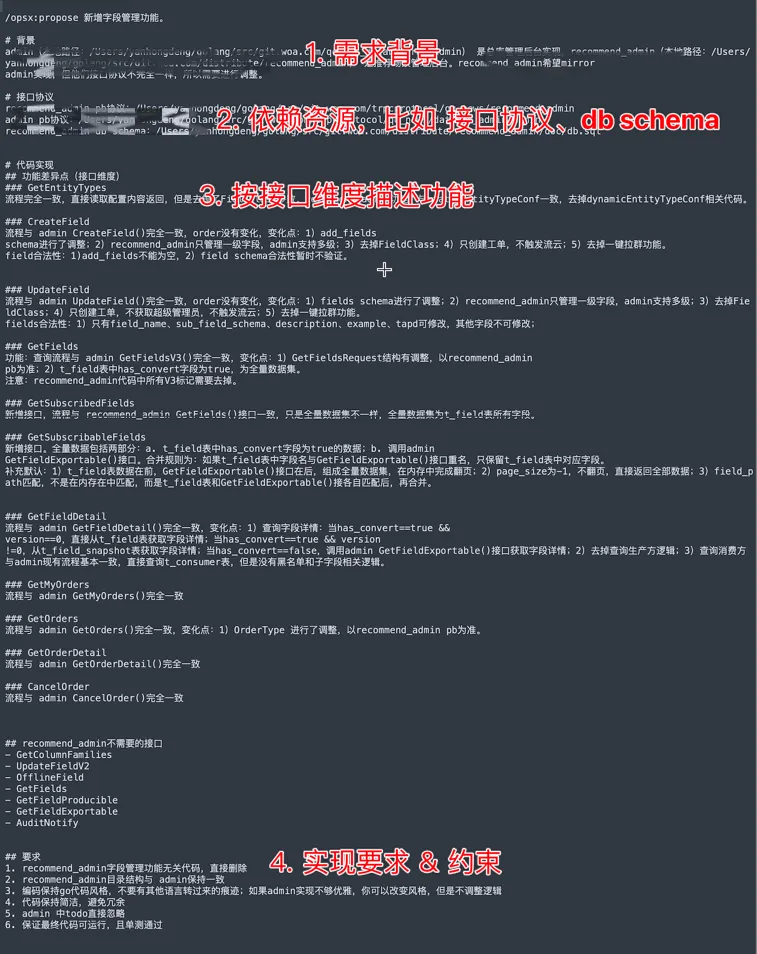
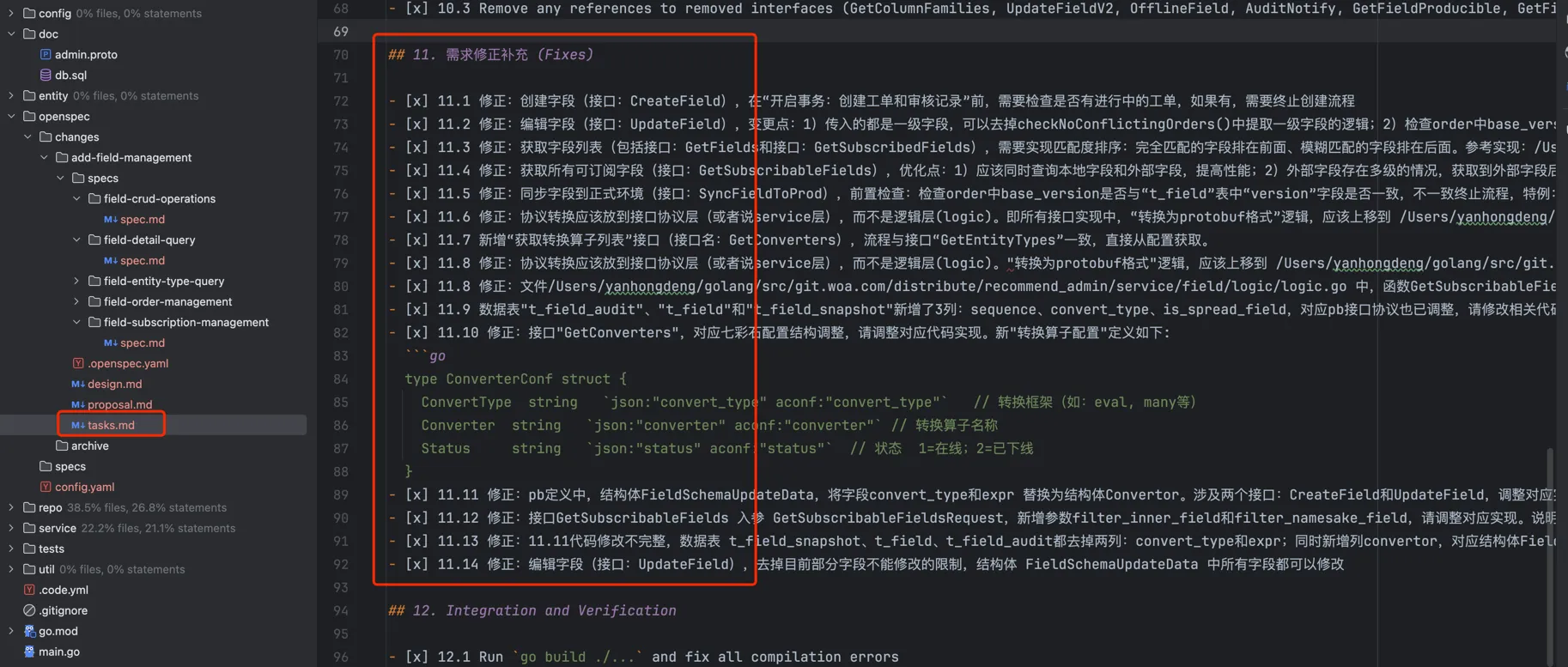
验证过程中发现,还是有部分功能缺失,直接在 tasks.md 中添加“修正说明”,然后让AI进行修复。
生成代码展示:
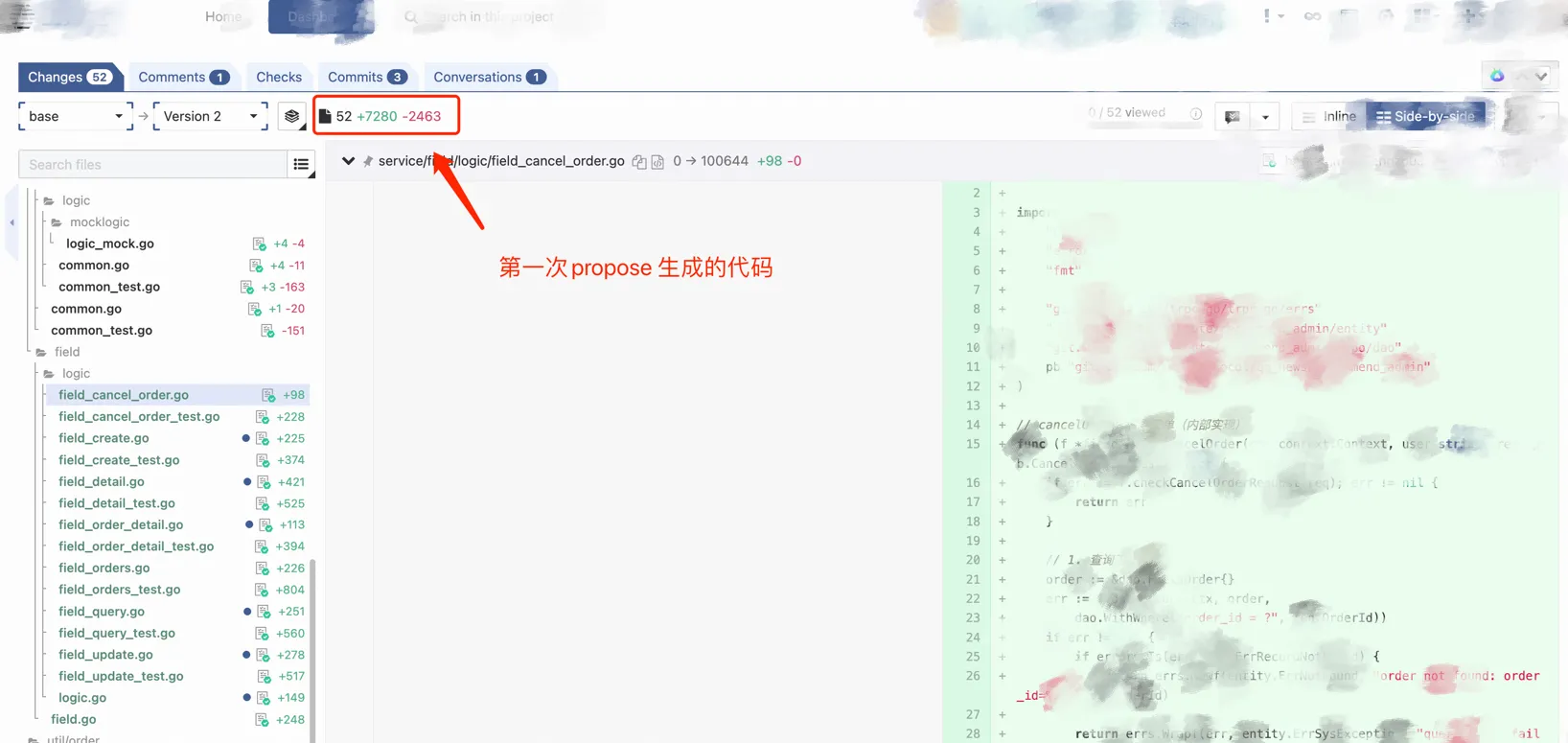
总共有两次MR,总共新增了 9600+ 行代码,我自己手动修改的 < 50 行(小调整通过spec描述,还不如直接修改高效),可以算是“全部代码由AI生成”。
下图是第一次propose生成的代码,新增7000+行,代码能编译通过,测试可以通过。
结果评测
评测维度说明:
- 代码正确性:功能是否按需求正确实现,边界条件是否处理
- 代码规范性:是否遵循项目编码规范,命名、格式、注释是否合理
- 可维护性:代码结构是否清晰,是否易于理解和修改
- 性能:是否存在明显的性能问题,如N+1查询、不必要的计算
- 安全性:是否存在SQL注入、XSS等安全漏洞
- 测试覆盖:生成的代码是否包含或易于编写单元测试
| 评测维度 | 实际结果(10制) | 差距分析 | 解决方案 |
|---|---|---|---|
| 功能完整性 | 完整度高,未随意发散,接口可调通(9分) | 缺少一定的”智慧”,未描述清楚的部分,没有基于”逻辑”补充完整。比如,不应该支持多人同时提交编辑,Spec中未强调,实现就未做对应限制 | 在 Spec 中补充隐含的业务规则和边界条件 |
| 代码规范性 | 符合规范(9分) | 1)缺少包注释;2)有一个函数超过80行。不符合”公司代码规范” | 在 config.yaml 中注入公司编码规范 |
| 可维护性 | 较高(8分) | 有2个大函数和部分重复代码 | Spec 中增加函数复杂度约束(如单函数不超过80行) |
| 性能 | 中等(9分) | 未明确说明并行,但多个独立数据源,可并发请求 | 在 framework-conventions.md 中说明 trpc.GoAndWait 用法 |
| 安全性 | 未发现安全问题(10分) | 无安全问题 | — |
| 测试覆盖 | 单测覆盖率约50%,单测可跑通(9分) | 单测可跑通,单测覆盖率70% | Spec 中明确要求测试覆盖率目标 |
遇到的典型问题
问题1:缺少内部框架知识
分析:此场景可以使用trpc.GoAndWait()简化代码,但是公开 LLM 的训练数据不包含企业内部框架。
可行的方案:
- 在
specs/中建立一份framework-conventions.md,描述框架的关键约定 - 提供典型的代码示例作为参考(few-shot),而非仅靠文字描述
- 【建议】长期来看,可以考虑用 RAG 或 MCP 工具将内部框架文档接入 AI 上下文
问题2:缺少代码分层和架构规范知识
分析:缺少接口协议层(用于转换内外部协议、实现协议防腐)。AI 生成的代码只关注功能实现,不考虑代码架构。
可行的方案:
- 提供分层模板:在
specs/中维护一份architecture.md,描述项目的分层架构、各层职责边界、典型文件结构 - 在 Spec 中显式声明分层要求:
技术约束: - 必须遵循三层架构:Service(协议层)→ Logic(业务层)→ Repository(数据层) - Service 层负责内外部协议转换,Logic 层不应直接感知外部协议格式 - 所有跨层数据传递通过 DTO 进行,禁止直接透传 Protobuf 结构体
问题3:Spec编写的粒度
分析:Spec写太粗,AI自由发挥空间过大,产出不可控;Spec写太细,相当于在用自然语言"写代码",失去了AI提效的意义。
建议:
- 接口层面:定义清楚入参、出参、异常情况
- 业务规则:用 Scenario 格式明确各场景预期行为
- 技术约束:明确技术栈、框架版本、编码规范
- 不要规定:具体的实现步骤、变量命名、代码行数
💡 Scenario 格式与 BDD 的关系:这里的 Scenario(WHEN…THEN…)本质上就是 BDD(Behavior-Driven Development)中 Feature → Scenario 的简化写法。BDD 强调用"行为描述"定义预期,SDD 继承了这一思想——用 Scenario 描述 Feature 在各种条件下的预期行为,作为 AI 生成代码的验收标准。可以说,SDD 的 Spec 就是 BDD 的 Feature 文件的演进形态,从"给测试框架读"变成了"给 AI 读"。
需求2:字段转换协议调整
需求实现
需求描述:
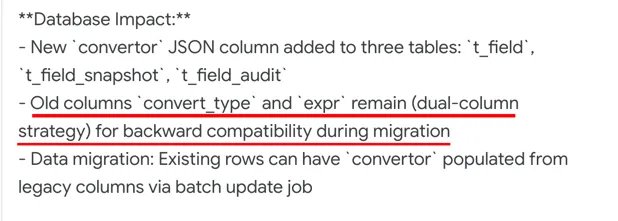
字段转换关系原来通过两个参数 convert_type 和 expr 描述,现在需要新增 “func_name” 参数(转换函数),因此希望将 3 个参数收归到一个结构体中(破坏性更新,删除旧字段)。
Spec 编写:
第一次编写的 Spec(未明确说明删除旧字段,AI采用了向后兼容模式):


第二次编写的Spec(明确删除旧字段,并手动更新了pb和db schema):

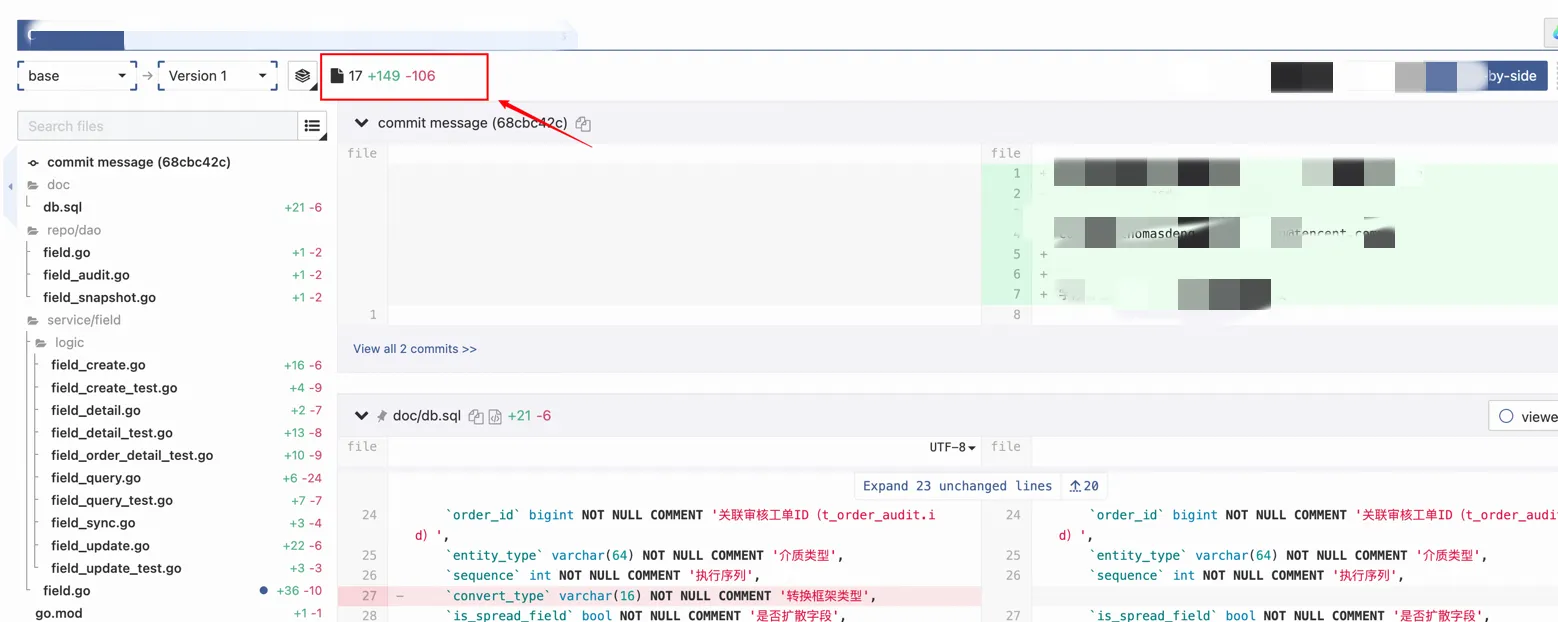
生成代码展示:
需求完整度很高,我没有做任何调整,直接进行了提交
结果评测
相比需求1(大需求、13个接口),需求2 是一个较小的重构需求。AI 生成的代码完整度很高,无需手动修改,直接提交。但也暴露了两个值得注意的问题(见下文)。
遇到的典型问题
问题1:AI理解与预期不一致
分析:AI 默认考虑“向后兼容”,实现本身没有问题,但是需求希望是“破坏性更新”,需要删除“convert_type”和“expr”
可行的方案:
- 提供最新的约束:【建议】提供最新的pb协议、db schema,或其他依赖资源,以免AI随意发挥
- Spec中明确说明:spec中明确说明删除旧字段(往往我们是以为很清楚了,实际 别人/AI 不一定清楚)
问题2:单测增量覆盖率不够
分析:Spec中并没有明确要求单测覆盖率,所以默认没有新增单测导致覆盖率不够
可行的方案:
- 在 CLI 中补充增量覆盖率要求
- 在 config.yaml中补充单测覆盖率要求,作为项目要求

总结与建议
SDD 的能力边界
诚实地讨论一下 SDD 适合和不适合的场景:
✅ 适合使用 SDD 的场景
| 场景 | 原因 |
|---|---|
| 需求明确的功能开发 | Spec 可以清晰定义预期行为,AI 产出质量高 |
| CRUD 和标准业务逻辑 | 模式化程度高,Spec → Code 转化率高 |
| 存量项目的功能迭代 | Delta 模型天然适合增量开发 |
| 有明确架构规范的项目 | 约束越清晰,AI 产出越可控 |
| 多人协作项目 | Spec 成为团队共识载体,减少沟通成本 |
❌ 不适合使用 SDD 的场景
| 场景 | 原因 |
|---|---|
| 探索性原型/POC | 需求本身不明确,写 Spec 的成本 > 直接写代码的成本 |
| 高度创新性的算法 | AI 对创新算法的理解有限,Spec 也难以精确描述 |
| 性能极致优化 | 涉及底层优化、汇编级调优,需要深度专业知识 |
| 遗留代码的紧急修复 | 小范围 hotfix 不值得走完整 SDD 流程 |
| 强依赖内部框架且无文档 | AI 无法理解未文档化的内部框架,Spec 再详细也无用 |
🟡 可以但需谨慎的场景
| 场景 | 建议 |
|---|---|
| 复杂业务逻辑 | SDD + 人工 Review 双重保障,不能盲目信任 AI 产出 |
| 涉及安全的模块 | 用 SDD 生成初版,但必须经过安全专家审查 |
| 跨系统集成 | Spec 中需详细描述外部系统的接口契约和异常处理 |
📌 判断标准:如果你能用 Spec 清晰描述"做什么"和"约束条件",SDD 就能帮你提效;如果连需求本身都说不清楚,那应该先花时间理清需求,而非急于使用任何工具。
对开发者的启示 —— 回归业务本质
从 IaaS、PaaS、SaaS、FaaS,到 AIaaS(Artificial Intelligence as a Service),所谓”平权”也好,所谓”基础设施”也好,作为软件工程师都更聚焦于“业务/商业”的本质。
也引出另一个问题:编程的本质是什么? 编程从来不只是”写代码”。代码只是思想的载体,是业务规则的具象化。编程的本质是将模糊的现实问题转化为精确的逻辑表达——理解需求、抽象建模、设计边界、处理异常、权衡取舍。这些才是软件工程师真正的核心价值。 写 Spec 的过程,就是在做问题定义、架构决策和边界判断;审查 AI 产出的过程,就是在做质量把控;维护 Spec 的过程,就是在做知识沉淀。
| 工程师的核心价值 | 具体表现 | AI 能否替代 |
|---|---|---|
| 问题定义 | 从模糊的业务需求中提炼出精确的技术问题 | ❌ 不能 |
| 架构决策 | 在多种方案中基于团队现状、系统约束做取舍 | ❌ 不能 |
| 边界判断 | 识别哪些是关键约束、哪些可以妥协 | ❌ 不能 |
| 质量把控 | 审查产出是否符合工程标准和业务预期 | 🟡 部分 |
| 知识沉淀 | 将隐性经验转化为可传承的规范和文档 | 🟡 部分 |
OpenSpec 使用建议
- 提供最新的依赖资源:pb 文件、db schema 等,约束越清晰明确,生成代码越准确
- 善用 config.yaml:手动将 pb 文件路径、db schema 等依赖信息添加到
openspec/config.yaml中,AI 每次都能自动读取 - 小改动不必走 SDD:较小的改动仍建议直接手动修改(后续积累的 spec 足够多,也许可以通过”简短描述”直接修改)
展望
SDD的演进方向
与CI/CD深度集成:未来Spec不仅驱动代码生成,还可以驱动测试生成、文档生成、甚至部署配置。Spec成为整个研发流水线的"源头活水"。
Multi-Agent协作的基石:在Multi-Agent架构中,Spec文档可以作为多个Agent之间的"协议"——Code Agent根据Spec写代码,Test Agent根据Spec写测试,Review Agent根据Spec做审查,保证各Agent行为一致。
Spec的自动演化:当前Spec需要人来维护更新。未来可能出现"Spec Agent",根据代码变更自动更新Spec,实现Spec与代码的双向同步。
行业标准化:目前OpenSpec和Spec-Kit各有格式标准。随着SDD被更多团队采用,社区可能会收敛出统一的Spec格式标准,类似于OpenAPI之于REST API。
SDD + TDD:传承与发展:SDD 并非对传统工程实践的否定,而是传承和发展。在 SDD 工作流中,完全可以结合 TDD——先从 Spec 生成测试用例(作为验收标准),再让 AI 生成实现代码,最后用测试验证代码正确性。这形成了 Spec → Test → Code 的闭环:Spec 定义"做什么",Test 定义"怎么验",AI 负责"怎么做"。TDD 为 SDD 的产出提供了自动化的质量保障网,两者结合比单独使用任何一个都更可靠。
写在最后
SDD 不是终点,而是 AI 辅助研发走向工程化的一个关键节点。从 Vibe Coding 的自由探索,到 SDD 的规范约束,我们正在找到"AI自由度"与"工程可控性"之间的平衡点。
这次初体验的核心收获:AI 的能力上限取决于你给它的约束质量。写好 Spec,比写好 Prompt 重要得多。
本文是 SDD 系列的第一篇,记录了"从零到跑通"的初体验。后续我们会继续深入实践,计划探索的方向包括:
- SDD + TDD 的结合实践:用 Spec 驱动测试生成,再用测试验证代码,形成完整闭环
- 大型项目的 Spec 治理:当 specs/ 目录膨胀后,如何组织和维护
- 团队协作中的 SDD 落地:如何在团队中推广 SDD,建立 Spec Review 机制
- config.yaml 的最佳实践:如何把内部框架知识、架构规范高效注入 AI 上下文