作为一名架构师,我经常被问到一个问题:“你的系统是怎么做到连续两年没有出过 P0/P1 级故障的?” 我们确实做了很多事情,但是一直没有进行系统的梳理,想趁此机会把思考、尝试讲出来。
一、 前言:“零故障"的幸存者
我目前负责的服务,系统承载着 10w+ QPS,服务 20 多个业务场景。曾经出现过热点事件,系统流量上涨50%;也出现过爬虫流量导致大量冷数据绕过缓存层直穿 DB(缓存穿透,Cache Penetration),系统成功率骤降。
系统经历这些"风暴”,都顺利挺过来了,我想真正的核心在于:我们业务盘点、预演,建立了一套能在悬崖边踩住刹车的底盘,确保了局部异常绝不会扩散为全局灾难(控制爆炸半径,Blast Radius)。
二、 重新认知"稳定性"
1. 稳定性 vs 高可用 在工程实践中,我们经常说的是"三高"中的"高可用",那高可用 与 稳定性是什么关系?
- 高可用: 核心是"能不能访问"(如 99.99% 的 SLA)。常见思路是"做加法",通过数据库一主多从、多 AZ 部署等物理冗余来避免单点故障(Avoid Failure),本质上是用成本(多副本)换生存。
- 稳定性: 核心是"综合表现是否可控"。除了能访问,还要保证 TP99 性能不劣化、数据不乱。面对洪峰和错误变更,依靠限流、熔断和业务降级(Graceful Degradation),用局部牺牲换取全局存活,这是面向失败的设计(Design for Failure),本质是一种妥协。
“高可用决定了系统在遇到硬件灾难时会不会’挂’,而稳定性决定了系统在面临流量洪峰、烂代码和复杂业务拉扯时,会不会走向’失控’。高可用可以花钱买服务器解决,但稳定性只能通过日复一日的技术敬畏心和严苛的工程治理来死守。”
2. 破除迷思:“稳定” ≠ “不出故障” 很多工程师有一个执念,认为"系统永远不坏"才是好架构。这其实是只停留在高可用层面的执念。真正的稳定,是承认"失败是必然发生的常态"。硬件会老化,网络会抖动,人会犯错,外部依赖会宕机。 “稳定性的核心不是避免一切故障,而是控制影响的半径,将不可控的灾难,转化为可控的故障。”
三、 他山之石:大厂稳定性理论速览
在进入实战复盘前,我们先对齐一下业界顶尖的稳定性流派,这是我们架构设计的"参考系":
- Google SRE 体系(度量与文化): 核心是 SLI/SLO 和 Error Budget(错误预算)。用软件工程的方法解决运维问题。
- 阿里/蚂蚁防御体系(变更与应急): 核心是"发布三板斧(可灰度、可观测、可回滚)“以及"1-5-10 应急响应机制”。
- Netflix 混沌工程(架构韧性): 核心是主动向生产环境注入故障(Chaos Monkey),逼迫架构实现无状态和高可用。
我们可以看到每家公司稳定性建设各有侧重。阿里经常有各种活动和大促,变更频繁且流量波动大,所以更聚焦"发布变更"和"紧急故障处理";Google 作为全球基础设施提供商,面向的是海量用户和极致的 SLA 承诺,因此更注重用数据量化稳定性目标(SLO),并通过 Error Budget 机制在"快速发布"与"稳定底线"之间建立制度约束;Netflix 则是流媒体业务,一次大规模宕机直接等于百万用户同时无法追剧,加之其微服务架构极为复杂,所以选择用混沌工程"以攻代守"——主动制造故障,逼迫每个服务都具备独立存活的能力。
理论很丰满,但实际业务不可能照单全收。我们的取舍是:从阿里体系借鉴了"发布三板斧"和 P0/P1 分级响应机制;从 Google SRE 借鉴了 SLO 量化思路,用来和业务方对齐"可以接受多少不稳定";混沌工程目前只在核心链路做了轻量级故障注入,尚未全面铺开。这种选择本身也是稳定性建设的一部分——用有限资源守住最重要的防线,而不是追求理论上的完美。
四、 实战复盘:
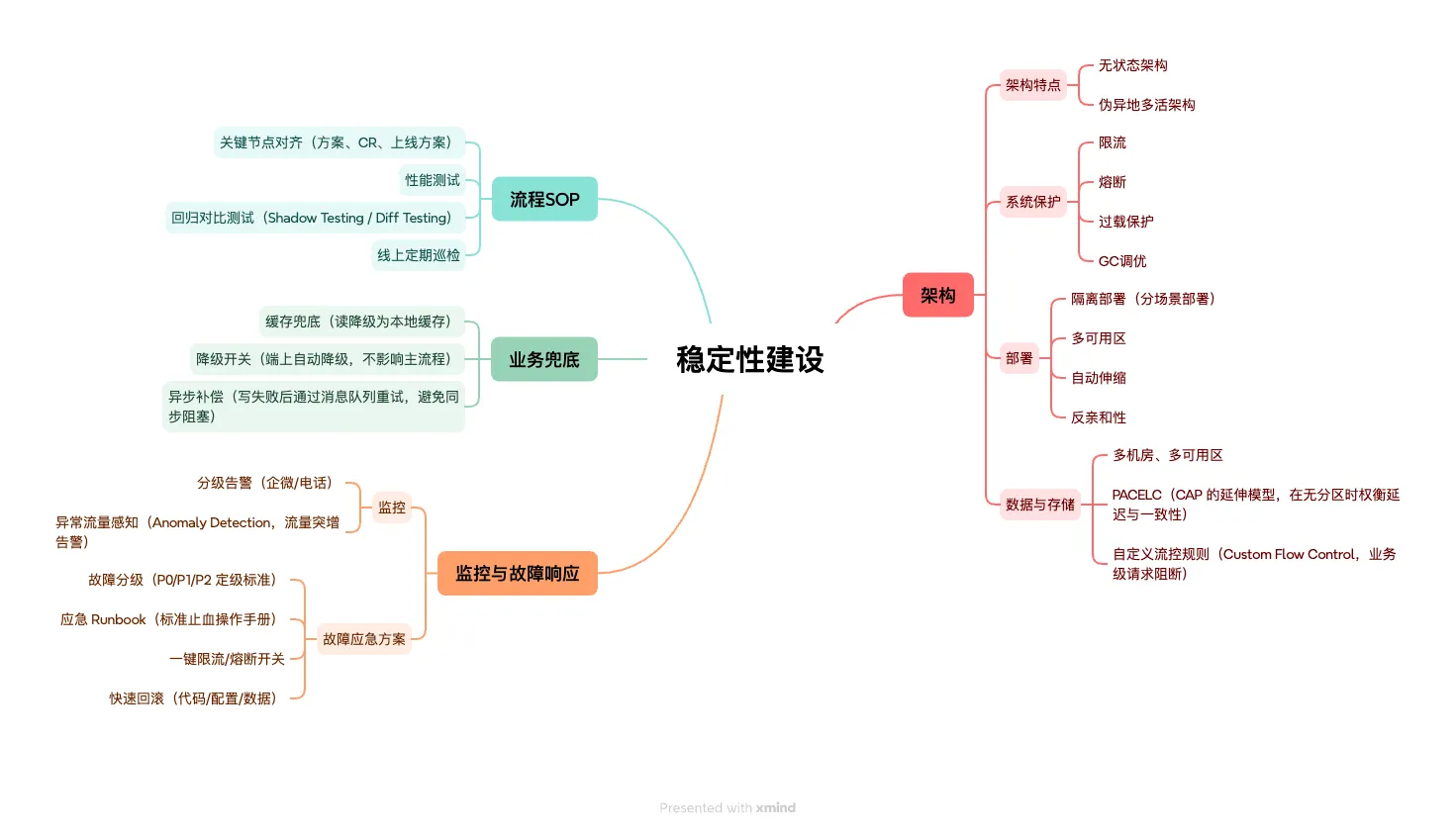
我认为一个稳定的系统是:架构、业务和流程,共同协同的结果。
- 架构是系统稳定性能力的基石,决定了系统的能力下限,它在技术层面限制了"最坏的情况有多坏";
- 业务是系统稳定性能力的护城河,决定了系统降级后能否体面存活——没有业务兜底,再好的架构也可能在极端情况下给用户一个白屏;
- 流程是稳定性能力的纪律线,通过标准化的研发 SOP 将稳定性要求嵌入每一次变更,把"人为失误"这个最大的不确定因素收敛到最小。
五、 新挑战:AI 时代的"防御性编程 2.0"
随着 Copilot 等 AI 编码助手的普及,研发效能狂飙,但隐患也被放大了。AI 生成的代码看似逻辑通顺,却常常带有极具隐蔽性的漏洞——尤其是两类:并发竞态(Race Condition),如多协程共享状态时的数据竞争;以及分布式状态机时序错乱,如跨服务的幂等性破坏和消息乱序处理。 过去我们认为加个 Lint 和静态分析就能拦截,但这套手段对付 AI 生成的代码无异于隔靴搔痒——静态扫描根本查不出分布式状态机的死锁,它需要运行时的多节点协同才能复现。
为了应对这些挑战,我认为稳定性建设进入了2.0阶段,核心思路是:让测试手段与问题类型精准匹配:
- 针对时序与边界问题——引入契约测试(Contract Testing)与模糊测试(Fuzzing): 契约测试用来卡死上下游服务的接口时序边界,防止 AI 生成的调用方和服务方对协议的理解产生隐性偏差;Fuzzing 则通过海量随机输入轰炸接口边界,暴露 AI 代码中潜藏的 panic 和非预期状态转移。
- 针对并发与运行时问题——强化静态分析与运行时检测: 引入 Race Detector(如 Go 的
-raceflag)作为 CI 强制门禁,在流水线阶段拦截并发竞态;对复杂状态机逻辑,要求补充状态转换图(State Machine Diagram)作为 Code Review 的强制输入,而非只看代码。 - 常态化混沌工程(Chaos Engineering)兜底: 在上述手段之上,定期通过故障注入(断网、高延迟、脏数据)对整体链路做健壮性压测,验证即便 AI 代码出现非预期行为,系统的熔断和隔离机制也能兜住,不至于扩散为全局故障。
六、 结语
稳定性建设就是一个对抗熵增的过程,也是一项"反人性"的工程。
说它"反人性",是因为它的大多数成果都是负向的——你做了很多事,用户感知不到任何变化,这才叫成功。没有故障,没有白屏,没有等待,一切顺滑如常。稳定性工作的最高境界,就是让人感觉它从来不存在。
坦诚地说,我也不认为现在的系统是完善的。当前还存在一些悬而未决的硬骨头:伪多活架构下数据库跨 AZ 同步的延迟问题,在极端网络抖动时 RPO(Recovery Point Objective)仍无法做到趋近于零。但"够用"与"完美"之间的取舍,本身就是稳定性建设的核心命题——把有限的资源投入到风险最高的地方,而不是追求面面俱到的理论完美。
系统会变,业务会变,团队会变,威胁也会变。我唯一确定的是:保持对系统的敬畏心,不要在一段平稳期之后开始觉得"应该没问题了"。历史上大多数严重故障,恰恰发生在一段长期稳定之后——因为人的警惕性降低了,而系统的复杂性还在悄悄积累。